P1 报告解读:从旋转曲线到弱透镜,如何检验 EFT 的平均引力响应
基于《P1_RC_GGL:星系动力学与弱透镜的严格闭合检验(v1.1)》撰写的面向公众解读版
查看原始评估报告:
1. ChatGPT: https://chatgpt.com/share/6a00c7d4-6240-83eb-9385-e9a1b76567ad
2. Gemini: https://gemini.google.com/share/066606dca612
3. Grok: https://grok.com/share/bGVnYWN5LWNvcHk_369f720b-c503-47e8-a040-18f0560141ea
4. 千问: https://chat.qwen.ai/s/9f9f59d9-1ef0-43db-a95d-111b918e0a2a?fev=0.2.46
5. DeepSeek: https://chat.deepseek.com/share/aw7lrq3igzhfqt418b
阅读说明 |
这是一篇“解读版”,不是另一篇学术报告。它以原始 P1 报告为基础,保留关键图表,并在每个关键环节补充“这意味着什么”的公众解释。 |
本文只解读 P1 在其既定数据集、参数账本与统计协议下得出的结论:在星系旋转曲线(RC)与星系—星系弱透镜(GGL)的联合检验中,EFT 的平均引力响应模型明显领先于本文所测试的最小 DM_RAZOR 基线。 |
本文不把 P1 解读成“推翻暗物质”的结论。P1 只是 P 系列实验的第一步,它测试的是 EFT 中“平均引力底座”这一个可观测层面,而不是 EFT 整体理论的全部内容。 |
0|先用 5 分钟理解 P1:这件事到底在做什么?
你可以把 P1 想成一次“跨探针互相验真”实验。它不是只问某个模型能不能拟合一套数据,而是把两种完全不同的引力读数放到同一个审计台上:旋转曲线(RC)读星系盘里的动力学,星系—星系弱透镜(GGL)读更大尺度上的投影引力响应。
- RC 像“车速表”:告诉我们星系盘里气体和恒星在不同半径处转得多快。
- GGL 像“体重秤”:通过背景光被前景星系轻微弯曲的程度,反推星系周围更大尺度的平均引力/质量分布。
- P1 的核心问题是:同一套模型,能否先从 RC 学到规律,再把这套规律迁移到 GGL 上仍然说得通?
P1 最核心的一句话 |
P1 把比较门槛从“单独拟合得好不好”提高到“跨探针能不能闭合”。正确映射下表现好、打乱映射后信号坍塌,才说明模型更可能抓到了 RC 与 GGL 之间共享的引力结构。 |
表 0|P1 的核心数字与普通读者读法
指标 | P1 / P1A 中的读法 | 普通读者怎么理解 |
联合拟合 ΔlogL_total | 正文主比较中 EFT 相对 DM_RAZOR 为 1155–1337 | 两套数据合起来的总得分差;越大表示整体解释更好。 |
闭合强度 ΔlogL_closure | 正文主比较中 EFT 为 172–281,DM_RAZOR 为 127 | 只用 RC 推断后能预测 GGL 的能力;越大越“跨探针自洽”。 |
负对照 shuffle | 打乱 RC-bin→GGL-bin 后,EFT 闭合信号降至 6–23 | 如果正确对应关系被破坏,优势应当消失;消失越明显,越能排除伪信号。 |
P1A 多 DM 压力测试 | DM 7+1 + DM_STD,并保留 EFT_BIN 对照 | P1A 不只看最小 DM_RAZOR,而是把多个低维可审计 DM 增强分支放进同一闭合协议。 |
1|为什么要做 P1:当前星系尺度宇宙学卡在哪里?
星系尺度的问题之所以长期难解,是因为“额外引力/质量需求”不只是一个旋转曲线现象。大量观测显示,星系中可见重子物质与实际动力学/透镜读数之间存在很紧的联系。对暗物质路线来说,这意味着暗晕、重子反馈、星系形成历史和观测系统误差必须被非常精细地协调;对非暗物质引力路线来说,这意味着模型不能只在 RC 上好看,还必须在弱透镜、群体标度律和负对照中继续成立。
这正是 P1 的动机:它不是从“暗物质错了”或“EFT 一定对”出发,而是把一块可检验命题拿出来受审——EFT 中的平均引力响应,是否能在 RC→GGL 的跨探针闭合中留下可复现、可迁移的信号。
外部文献背景:为什么 RC+GGL 这一窗口重要? |
McGaugh、Lelli 与 Schombert 2016 年提出的径向加速度关系(RAR)显示,旋转曲线追踪的观测加速度与重子物质预测的加速度之间存在紧密相关,且散布很小。这让“重子—引力响应耦合”成为星系尺度理论绕不开的问题。 |
Brouwer 等 2021 年用 KiDS-1000 弱透镜把 RAR 延伸到更低加速度、更大半径区域,并比较 MOND、Verlinde emergent gravity 与 LambdaCDM 模型;他们同时指出早型/晚型星系差异、气体晕和星系—晕连接仍是关键解释问题。 |
Mistele 等 2024 年进一步用弱透镜反推孤立星系圆速度曲线,报告其在数百 kpc 乃至约 1 Mpc 尺度仍无明显下降,并与 BTFR 相符。这说明弱透镜正在成为检验星系尺度引力响应的重要外部读数。 |
因此,P1 的价值不在于“第一个把 RC 和 GGL 放在一起讨论”,而在于把它们放进一套固定映射、参数账本、RC-only→GGL 闭合、shuffle 负对照与 P1A 多 DM 压力测试组成的可审计协议里。
2|EFT 在 P1 里是什么意思?它不是 Effective Field Theory
这里的 EFT 指 Energy Filament Theory(能量丝理论),不是物理学里常见的 Effective Field Theory(有效场论)。在 P1 技术报告中,EFT 的使用非常克制:它不是以完整终极理论的形式参赛,而是先被压缩成一个可观测、可拟合、可被反驳的“平均引力响应”参数化。
换成普通语言就是:P1 先不讨论额外引力的全部微观来源,也不试图一次性证明整套 EFT;它只问一个更窄、更硬的问题——如果星系尺度上存在某种平均额外引力响应,那么它能不能先解释 RC,再迁移预测 GGL?
P1 抓的是 EFT 的哪一部分? |
P1 抓的是“平均引力底座”(mean gravity floor):一种统计上稳定、可跨样本迁移的平均贡献。 |
P1 暂不处理“噪音底座”(stochastic / noise floor):也就是更微观涨落过程可能带来的随机项、个体差异或额外散度。 |
P1 也不讨论完整微观机制、丰度、寿命或宇宙学全局约束。它是 P 系列实验的第一步,而不是终局宣判。 |
3|P1 系列计划:为什么第一步要从“平均底座”开始?
P 系列可以理解为 EFT 观测检索计划。它不是一次把所有命题摊开,而是先把最容易被公共数据检验的一块单独拎出来。P1 的策略是先测试平均项:如果平均引力响应连 RC→GGL 都不能闭合,那么继续讨论更复杂的噪音项或微观机制就缺少入口。
表 1|P 系列的分层定位
层级 | 要问的问题 | P1 中的位置 |
P1 | 平均引力响应是否能在 RC→GGL 中闭合? | 当前报告的主问题 |
P1A | 把 DM 侧做强一点,结论是否仍稳? | 附录 B:DM 7+1 + DM_STD 压力测试 |
后续 P 系列 | 是否能扩展到更多数据、更多探针、更复杂系统误差? | 后续工作方向 |
更深层问题 | 平均项与噪音项、微观机制如何连接? | 不属于 P1 的结论范围 |
4|数据是什么?RC 和 GGL 各自告诉我们什么?
4.1 旋转曲线 RC:星系盘里的“转速尺”
旋转曲线记录的是:在距离星系中心不同半径处,气体和恒星绕中心转得多快。转得越快,意味着那个半径处需要越强的向心力,也就是更强的有效引力。P1 使用 SPARC 数据库,经预处理后纳入 104 个星系、2295 个速度数据点,并划分为 20 个 RC-bin。
4.2 弱透镜 GGL:更大尺度上的“引力体重秤”
星系—星系弱透镜测量的是前景星系如何轻微弯曲背景星系光线。它对应的是更大尺度、晕尺度上的投影引力响应,不依赖星系气体动力学细节。P1 使用 KiDS-1000 / Brouwer 等 2021 的公开 GGL 数据:4 个恒星质量 bin,每个 bin 15 个半径点,总计 60 个数据点,并使用完整协方差。
4.3 固定映射:为什么 20 个 RC-bin → 4 个 GGL-bin 很关键?
P1 把 20 个 RC-bin 与 4 个 GGL-bin 通过固定规则连接:每个 GGL-bin 对应 5 个 RC-bin,并按星系数权重加权平均。这个映射对所有模型保持不变,是闭合检验和公平比较的硬约束。
为什么不能事后调映射? |
如果允许事后选择“哪些 RC-bin 对应哪些 GGL-bin”,模型就可能通过调配对应关系来制造闭合。P1 预先锁定 20→4 映射,并用 shuffle 负对照故意破坏它,正是为了判断闭合信号是否真的依赖物理上合理的对应关系。 |
5|模型与方法:P1 到底在“比什么”?
5.1 EFT 侧:低维平均引力响应
EFT 侧使用一个低维额外速度项来描述平均引力响应:额外项的形状由无量纲核函数 f(r/ℓ) 控制,ℓ 是全局尺度,幅度按 RC-bin 给出。不同核函数代表不同起始斜率、过渡快慢和长程尾部,用于稳健性压力测试。
5.2 DM 侧:正文主比较与附录 P1A 必须分开读
正文主比较中的 DM_RAZOR 是最小化、可审计的 NFW 基线:固定 c–M 关系,不包含 halo-to-halo scatter、绝热收缩、反馈 core、非球形或环境项。这个设计的优点是自由度受控、容易复现;缺点是不能代表所有 LambdaCDM 或所有暗物质晕模型。
因此,在附录 B(P1A)里,我们把 DM 侧做成一组“标准化压力测试”:在不改变共享映射与闭合协议的前提下,逐步加入 SCAT、AC、FB、HIER_CMSCAT、CORE1P、lensing m 与组合基线 DM_STD 等低维增强分支,并保留 EFT_BIN 作为对照。你可以把 P1A 理解为:不是只拿一个最小 DM 基线来比,而是把一组常见、可审计的 DM 机制放进同一把“闭合尺子”里测一遍。
本文采用的准确结论口径 |
正文:EFT 系列在主比较中显著优于最小 DM_RAZOR。 |
附录 B / P1A:在多个低维、可审计的 DM 增强分支与 DM_STD 压力测试下,DM 的部分联合拟合可改善,但闭合强度没有消除 EFT_BIN 的优势。 |
因此最稳妥的表述是:在 P1/P1A 的数据、映射、参数账本与闭合协议范围内,EFT 平均引力响应表现出更强的跨数据一致性;这并不等于排除所有暗物质模型。 |
5.3 闭合检验:P1 最重要的实验语法
1. 只用 RC 做拟合,得到一组 RC-only 后验样本。
2. 不允许再用 GGL 重新调参,直接拿 RC 后验去预测 GGL。
3. 用完整协方差计算正确映射下的 GGL 预测得分 logL_true。
4. 把 RC-bin→GGL-bin 对应关系随机置换,计算负对照 logL_perm。
5. 把两者相减得到闭合强度:ΔlogL_closure = <logL_true> − <logL_perm>。
通俗比喻 |
闭合检验像一次跨考场复试:模型先在 RC 考场学习规律,再去 GGL 考场作答。如果它真的学到的是共享规律,而不是局部技巧,那么换考场后仍应该答得好;如果把考场对应关系故意打乱,优势就应该消失。 |
5.4 读技术表之前:四个入口先抓住
表 5.4|下一组横排技术表的阅读路线
入口 | 看什么 | 为什么重要 |
表 S1a | RC+GGL 联合拟合总分 | 回答“两套数据一起看,谁的整体解释更强”。 |
表 S1b | 闭合强度、shuffle、稳健性扫描 | 回答“RC 学到的东西能不能迁移到 GGL”。 |
表 B0 | P1A 中多个 DM 增强分支的定义 | 避免把 P1 简化成“只和最小 DM_RAZOR 比”。 |
表 B1 | P1A 的闭合与联合 scoreboard | 检查增强 DM 后,闭合优势是否被消除。 |
排版说明 |
下一页开始使用横向页面,是为了完整保留原报告中的宽表,避免删列或压缩到不可读。正文解读已经先给出普通读者版读法;横向技术表用于需要核对数值和模型分支的人。 |
图 0.1|一张图读懂 P1 的闭合检验流程
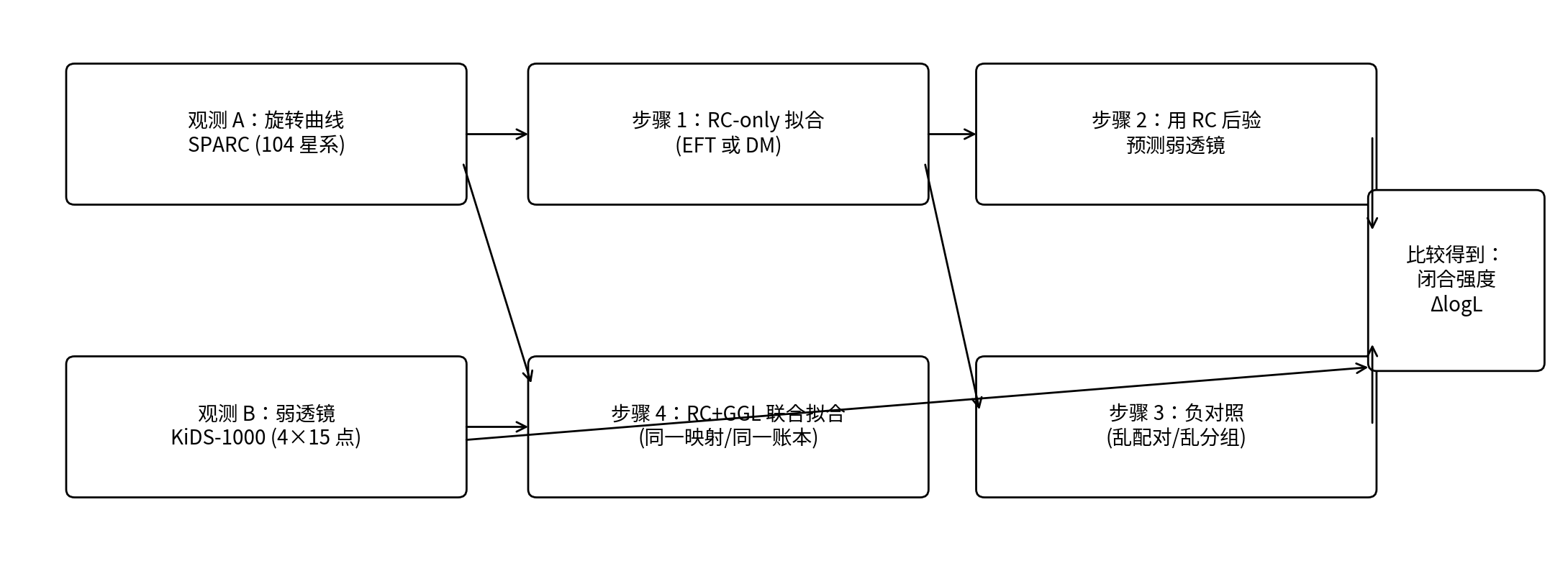
说明:上半条链是“闭合检验”(只用 RC 拟合 → 用 RC 后验预测 GGL);下半条链是“联合拟合”(RC+GGL 一起打分)。右侧把真实映射与打乱映射相比,得到闭合强度 ΔlogL。
6|关键技术表:原报告主表与 P1A 表格
表 S1a|联合拟合主比较指标(RC+GGL,Strict;保留自原报告)
模型(workspace) | W核 | k | 联合logL_total(best) | ΔlogL_total vs DM | AICc | BIC |
DM_RAZOR | none | 20 | -16927.763 | 0.0 | 33895.885 | 34010.811 |
EFT_BIN | none | 21 | -15590.552 | 1337.21 | 31223.501 | 31344.155 |
EFT_WEXP | exponential | 21 | -15668.83 | 1258.932 | 31380.057 | 31500.711 |
EFT_WYUK | yukawa | 21 | -15772.936 | 1154.827 | 31588.268 | 31708.922 |
EFT_WPOW | powerlaw_tail | 21 | -15633.321 | 1294.442 | 31309.038 | 31429.692 |
表 S1b|闭合与稳健性指标(Strict;保留自原报告)
模型(workspace) | 闭合ΔlogL(true-perm) | 负对照shuffle后ΔlogL | σ_int扫描ΔlogL范围 | R_min扫描ΔlogL范围 | cov-shrink扫描ΔlogL范围 |
DM_RAZOR | 126.678 | 22.725 | — | — | — |
EFT_BIN | 231.611 | 14.984 | 459–1548 | 1243–1289 | 1337–1351 |
EFT_WEXP | 171.977 | 6.04 | 408–1471 | 1169–1207 | 1259–1277 |
EFT_WYUK | 179.808 | 14.688 | 380–1341 | 1065–1099 | 1155–1166 |
EFT_WPOW | 280.513 | 6.672 | 457–1500 | 1203–1247 | 1294–1308 |
表 B0|P1A 中 DM 增强分支定义(保留自原报告附录 B)
Workspace | dm_model | 新增参数(≤1) | 物理动机(核心) | 实现原则(审计友好) |
DM_RAZOR | NFW (fixed c–M, no scatter) | — | 最小化、可审计的 LambdaCDM 晕基线;用于与 EFT 做严格对照 | 共享映射固定;参数账本严格;作为 baseline 仅用于相对比较 |
DM_RAZOR_SCAT | NFW + c–M scatter(legacy) | σ_logc | c–M 关系存在弥散;用一参 log-normal scatter 近似 | ≤1 新参;仍用共享映射;以闭合增益为验收标准 |
DM_RAZOR_AC | NFW + Adiabatic Contraction(legacy) | α_AC | 重子落入可能引发晕绝热收缩;用一参强度近似 | ≤1 新参;不改映射;报告 AICc/BIC 变化与闭合增益 |
DM_RAZOR_FB | NFW + feedback core(legacy) | log r_core | 反馈可在内区形成 core;用一参 core 尺度近似 | ≤1 新参;闭合/负对照同口径;不以 RC-only 改善为唯一目标 |
DM_HIER_CMSCAT | Hierarchical c–M scatter + prior | σ_logc(hier) | 更标准的层级化 c_i∼logN(c(M_i),σ_logc);同时影响 RC 与 GGL 联合后验 | 显式先验;latent c_i 边缘化;仍保持低维可审计 |
DM_CORE1P | 1‑parameter core proxy (coreNFW/DC14‑inspired) | log r_core | 用一参 core 代理 baryonic feedback 主效应,避免高维星形成细节 | 引用标准文献;≤1 新参;与闭合检验绑定 |
DM_RAZOR_M | NFW + lensing shear‑calibration nuisance | m_shear(GGL) | 将弱透镜端关键系统误差以有效参数吸收,降低“把系统误差当物理”风险 | nuisance 明确记账;不允许反向影响 RC;结果以闭合稳健为主 |
DM_STD | Standardized DM baseline (HIER_CMSCAT + CORE1P + m) | σ_logc + log r_core (+ m_shear) | 把最常见三类常见质疑同时纳入一个仍低维的标准基线 | 参数账本+信息准则齐报;闭合为主指标;作为最强 DM 防御对照 |
表 B1|P1A scoreboard(越大越好;保留自原报告附录 B)
模型分支(workspace) | Δk | RC-only best logL_RC (Δ) | 闭合强度 ΔlogL_closure (Δ) | Joint best logL_total (Δ) |
DM_RAZOR | 0 | -15702.654 (+0.000) | 122.205 (+0.000) | -27347.068 (+0.000) |
DM_RAZOR_SCAT | 1 | -15702.294 (+0.361) | 121.236 (-0.969) | -23153.311 (+4193.758) |
DM_RAZOR_AC | 1 | -15703.689 (-1.035) | 121.531 (-0.674) | -23982.557 (+3364.511) |
DM_RAZOR_FB | 1 | -15496.046 (+206.609) | 129.454 (+7.249) | -27478.531 (-131.463) |
DM_HIER_CMSCAT | 1 | -15702.644 (+0.010) | 121.978 (-0.227) | -23153.160 (+4193.908) |
DM_CORE1P | 1 | -15723.158 (-20.504) | 122.056 (-0.149) | -27336.258 (+10.810) |
DM_RAZOR_M | 0 (+m) | -15702.654 (+0.000) | 122.205 (+0.000) | -27340.451 (+6.617) |
DM_STD | 2 (+m) | -15832.203 (-129.549) | 105.690 (-16.515) | -22984.445 (+4362.623) |
EFT_BIN | 1 | -14631.537 (+1071.117) | 204.620 (+82.415) | -19001.142 (+8345.926) |
如何读表 B1(P1A scoreboard) |
• Δk:新增自由度(越大代表模型更复杂;更复杂不等于更好)。 • 重点看两列:闭合强度 ΔlogL_closure(Δ)(越大越“迁移自洽”)与 Joint best logL_total(Δ)(联合拟合总分)。 • 括号里的 (Δ) 表示相对 DM_RAZOR 的差值,便于直接比较。 |
• 这张表最想回答的问题是:当 DM 基线被“合理增强”后,闭合优势会不会消失。 • 读法提示:DM_STD 的联合得分提升很明显,但闭合强度反而下降;EFT_BIN 在闭合强度上仍保持更高。 |
一句话总结:在这组低维、可审计的 DM 增强范围内,提升联合拟合并不自动带来更强闭合;闭合(可迁移性)仍是关键判据。 |
7|主要结果怎么读?
7.1 联合拟合:两套数据一起看,EFT 主比较得分更高
表 S1a 与图 S4 显示,在同样数据、同一共享映射、近似同样参数规模下,EFT 系列相对 DM_RAZOR 的联合 ΔlogL_total 为 1155–1337。普通读者可以把它理解为:在 RC 与 GGL 两套数据合起来的同一评分规则下,EFT 主比较模型总分更高。
7.2 闭合检验:P1 最想强调的是“可迁移性”
闭合强度高,说明模型只用 RC 推断出的参数,不重新看 GGL,也能更好地预测 GGL。P1 报告中 EFT 的 ΔlogL_closure 为 172–281,DM_RAZOR 为 127。这个结果比“各自拟合都不错”更重要,因为它限制了模型在第二套数据上的自由度。
7.3 负对照:为什么“信号坍塌”反而是好事?
P1 把 RC-bin→GGL-bin 的分组对应关系随机打乱后,EFT 的闭合信号降至 6–23 的量级。对普通读者来说,这一步相当于“反作弊”:如果闭合优势只是代码、单位、协方差或拟合偶然造成的,那么打乱对应关系也可能照样有优势;但实际结果是优势坍塌,说明它依赖正确映射。
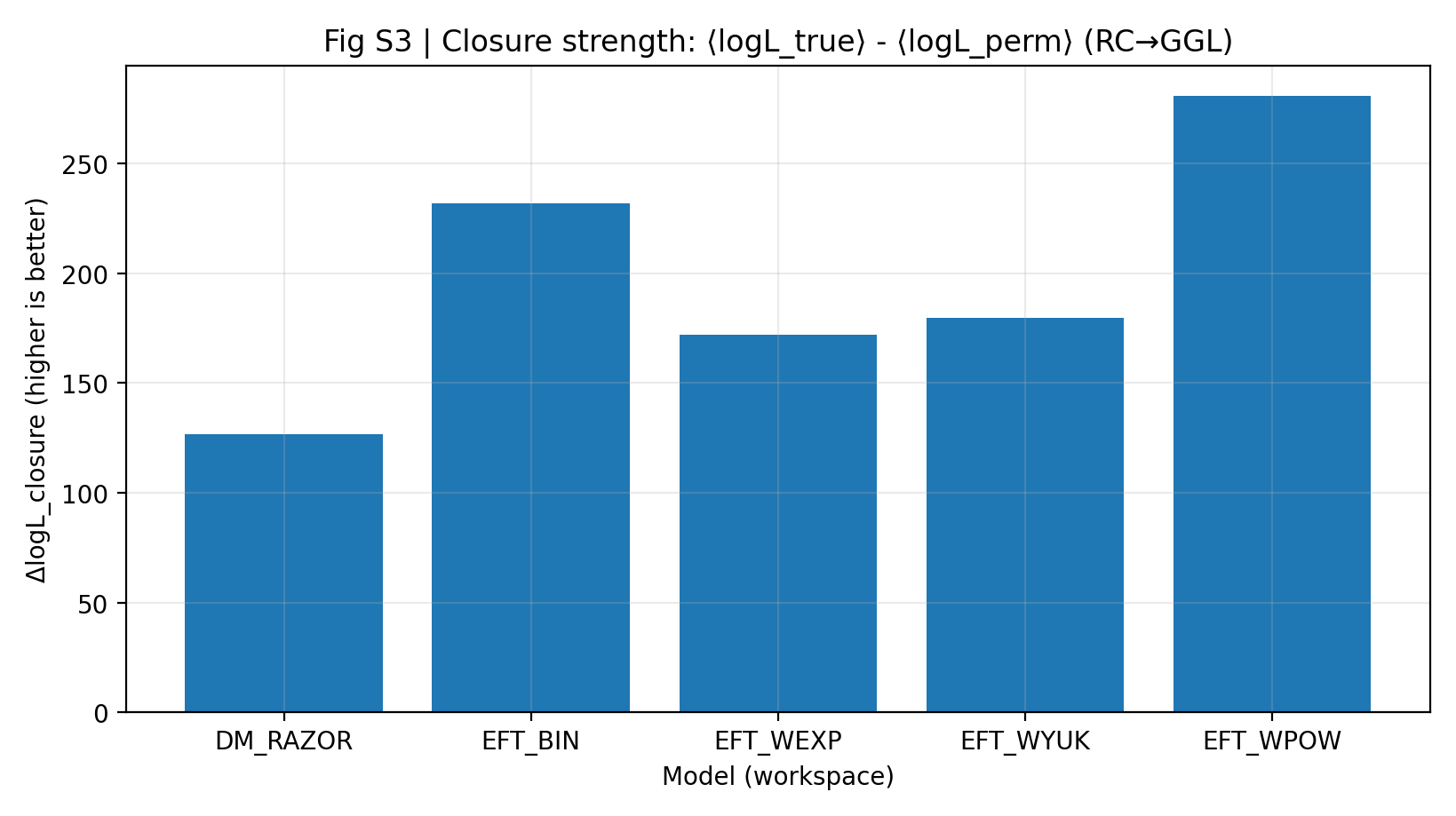
图 S3|闭合强度(越大越好):RC-only → GGL 预测的平均对数似然优势。
如何解读这张图 |
这张图是 P1 的核心。柱子越高,表示模型从 RC 学到的信息越能迁移到 GGL。 |
EFT 系列整体高于 DM_RAZOR,说明在“先学 RC,再预测 GGL”的实验中,EFT 的跨探针闭合更强。 |
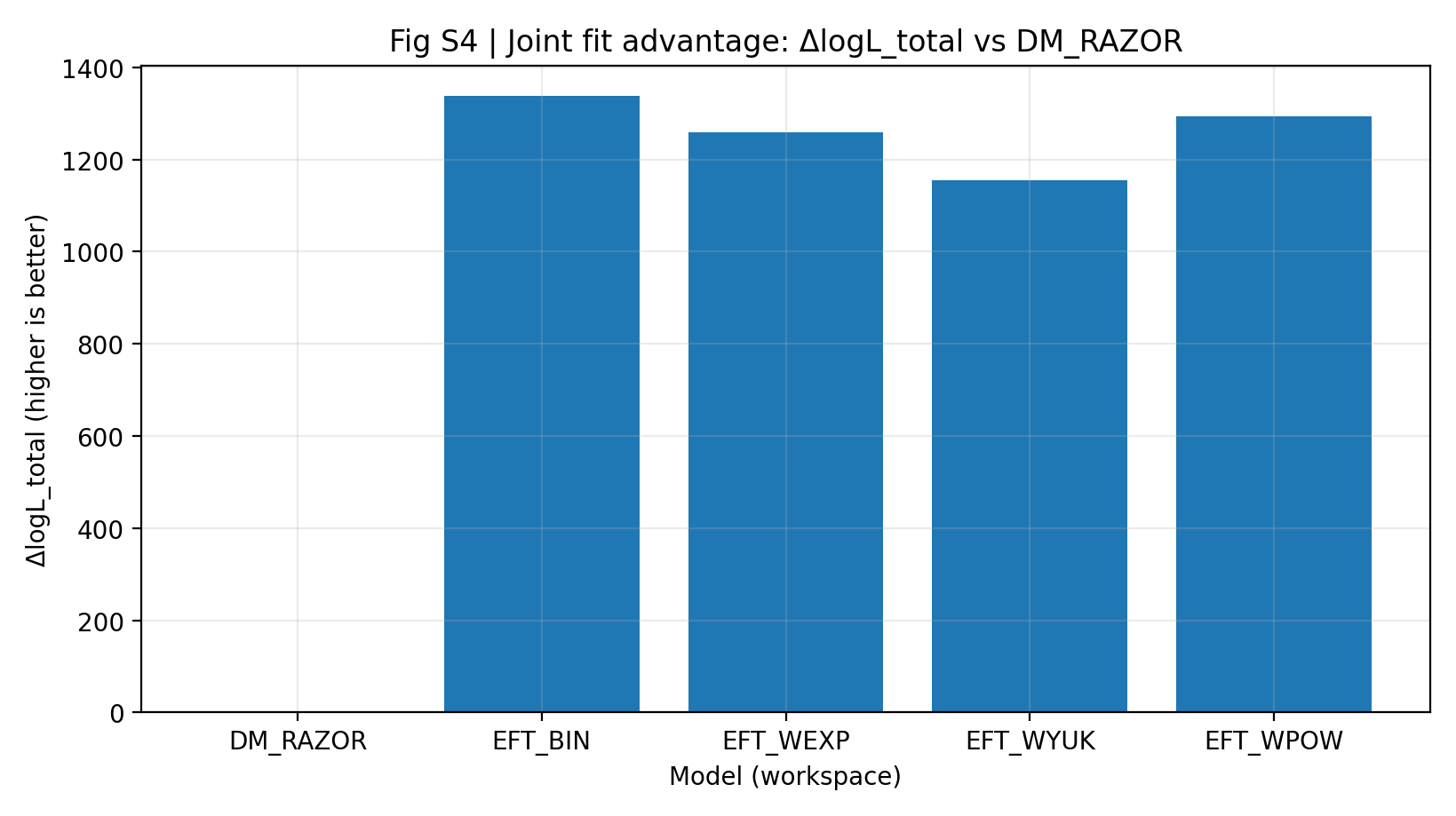
图 S4|联合拟合优势(越大越好):RC+GGL 的 best logL_total 相对 DM_RAZOR。
如何解读这张图 |
这张图看的是 RC 与 GGL 联合后的总得分。 |
EFT 系列全部显著高于 0,说明主比较中 EFT 的优势不是某个单点局部现象,而是联合分析的总体表现。 |
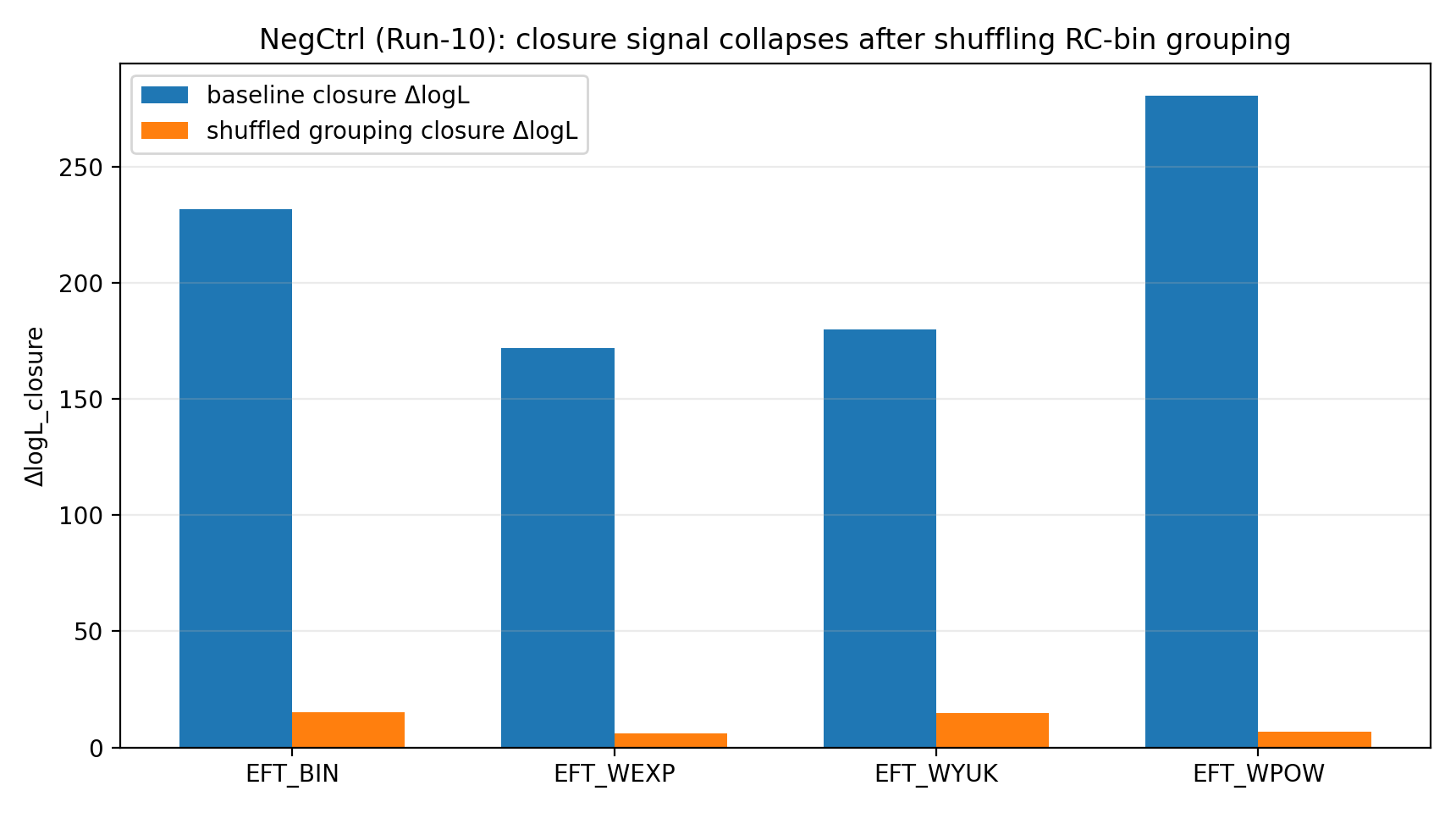
图 R1|负对照:shuffle 分组后闭合信号显著降低。
如何解读这张图 |
这张图说明,一旦打乱正确的 RC↔GGL 分箱关系,闭合信号会显著下降。 |
这使得 P1 结果更像跨数据映射中的真实一致性,而不是任意映射都能得到的数值巧合。 |
8|稳健性与对照:P1 如何避免“只是调参好看”?
一份技术报告最容易被质疑的地方是:优势会不会来自某个噪声设定、某段中心区数据、某种协方差处理,或者过拟合?P1 用多组压力测试来回答这个问题。
表 2|P1 的稳健性与负对照读法
测试 | 它想排除什么疑问 | 读法 |
σ_int 扫描 | 如果 RC 里存在额外未知散度,结论是否还稳? | 放宽 RC 误差后,EFT 排序与优势量级保持稳定。 |
R_min 扫描 | 如果不完全信任星系中心区,结论是否还稳? | 裁剪中心区后,EFT 仍保持正优势。 |
cov-shrink 扫描 | 如果 GGL 协方差估计有不确定性,结论是否还稳? | 协方差向对角阵收缩后,优势不敏感。 |
消融阶梯 | EFT 是否靠无必要复杂度硬拟合? | 完整 EFT_BIN 在信息准则上有必要性。 |
LOO 留出预测 | 模型是否只会解释见过的数据? | 留出 GGL bin 后仍显示较强泛化表现。 |
RC-bin shuffle | 闭合是否来自真实映射? | 打乱分组后闭合下降,支持映射依赖性。 |
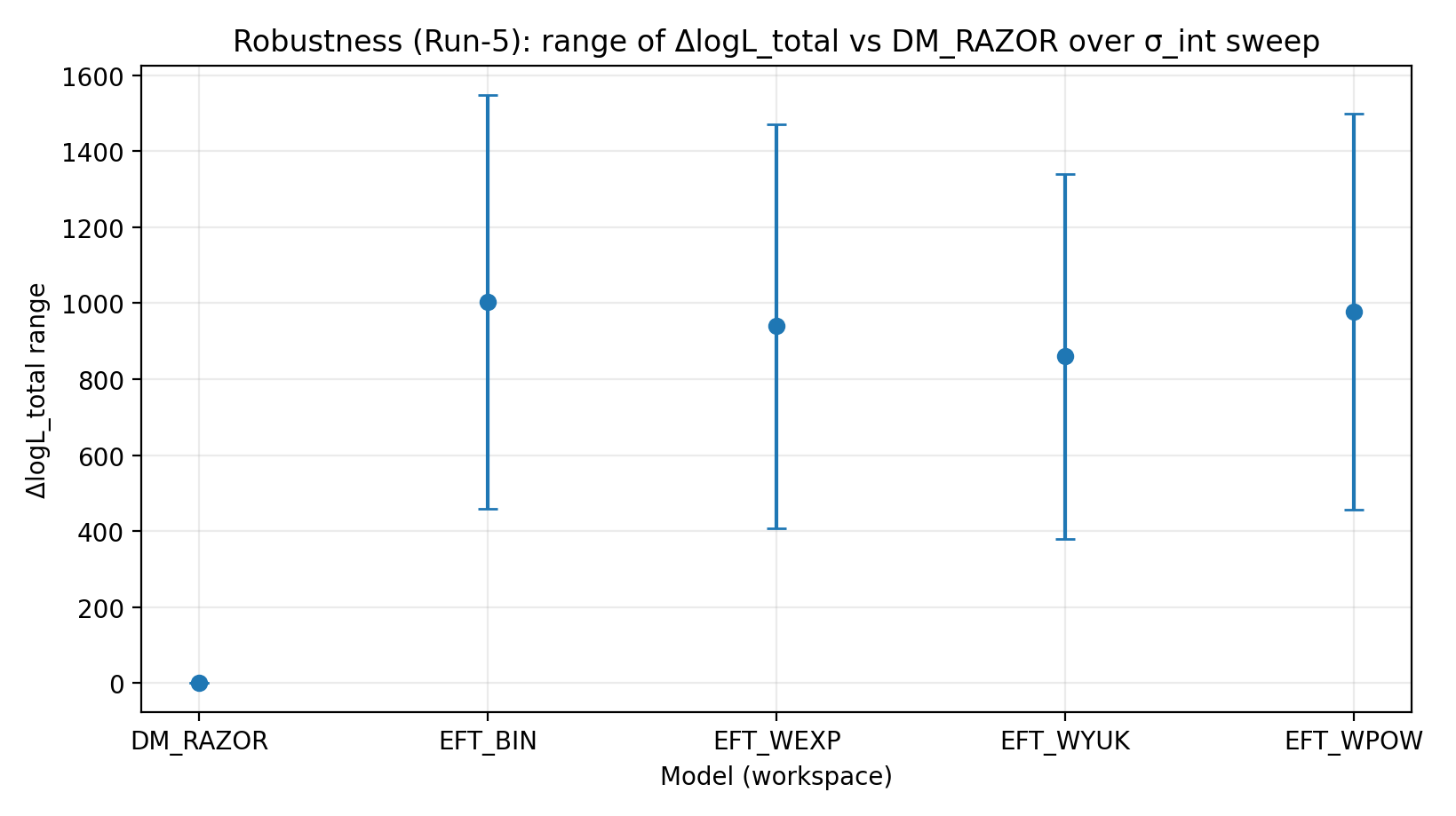
图 R2|σ_int 扫描下 ΔlogL_total 的范围(越大越好)。
如何解读这张图 |
检验 RC 内禀散度设定变化后,EFT 的领先是否还在。 |
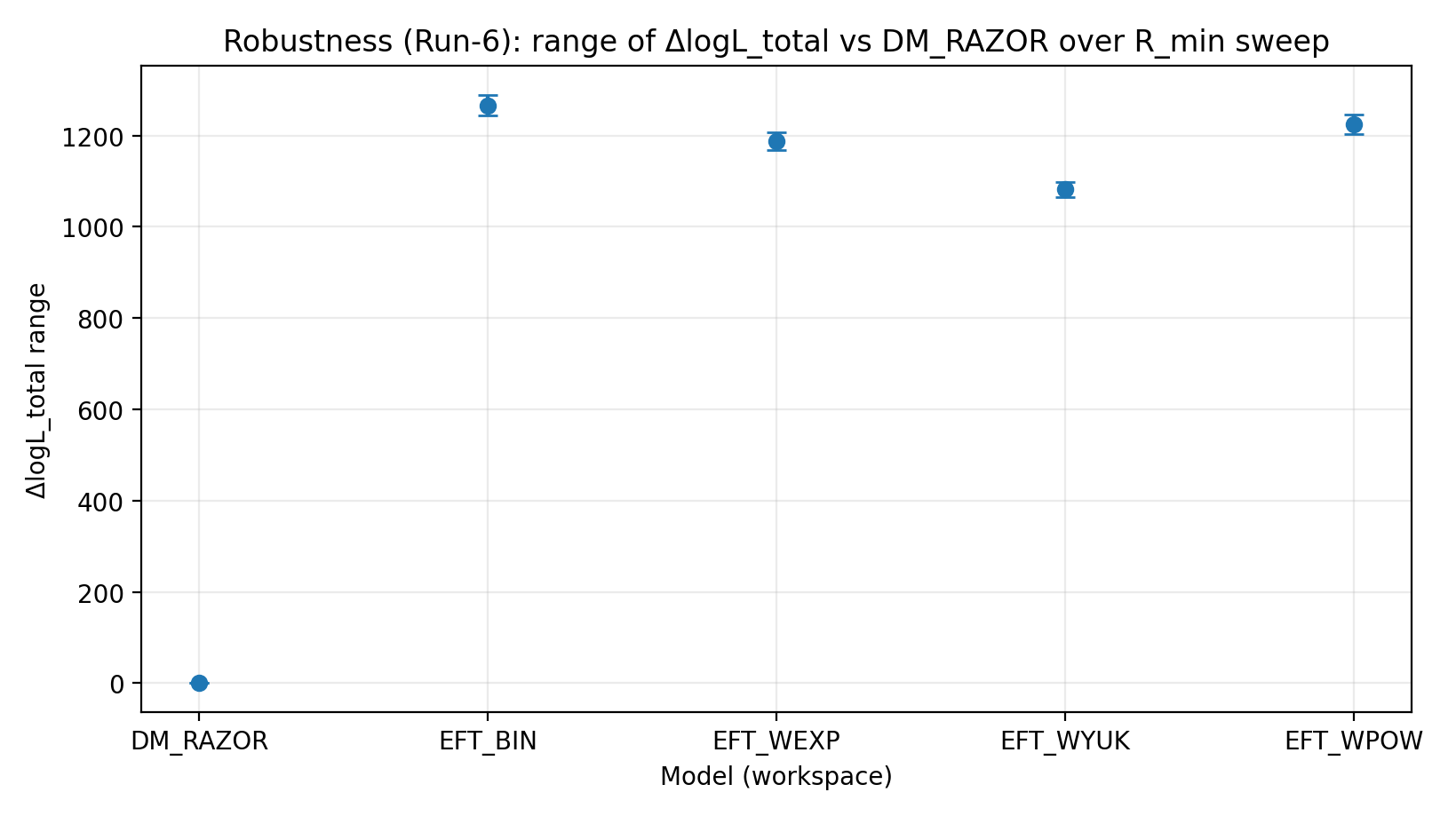
图 R3|R_min 扫描下 ΔlogL_total 的范围(越大越好)。
如何解读这张图 |
检验裁剪复杂中心区后,EFT 的优势是否仍稳定。 |
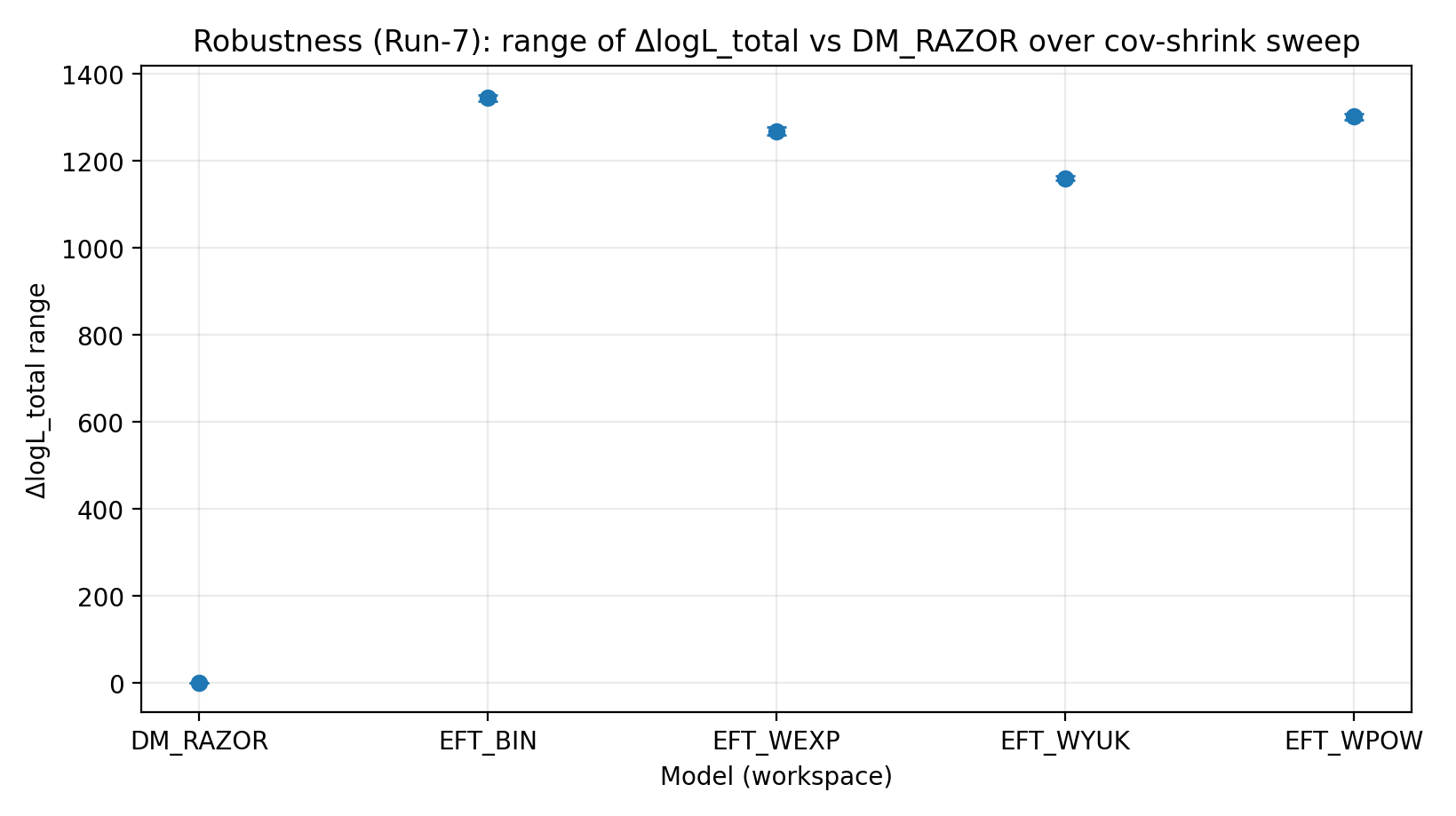
图 R4|cov-shrink 扫描下 ΔlogL_total 的范围(越大越好)。
如何解读这张图 |
检验弱透镜协方差处理变化后,排序是否敏感。 |
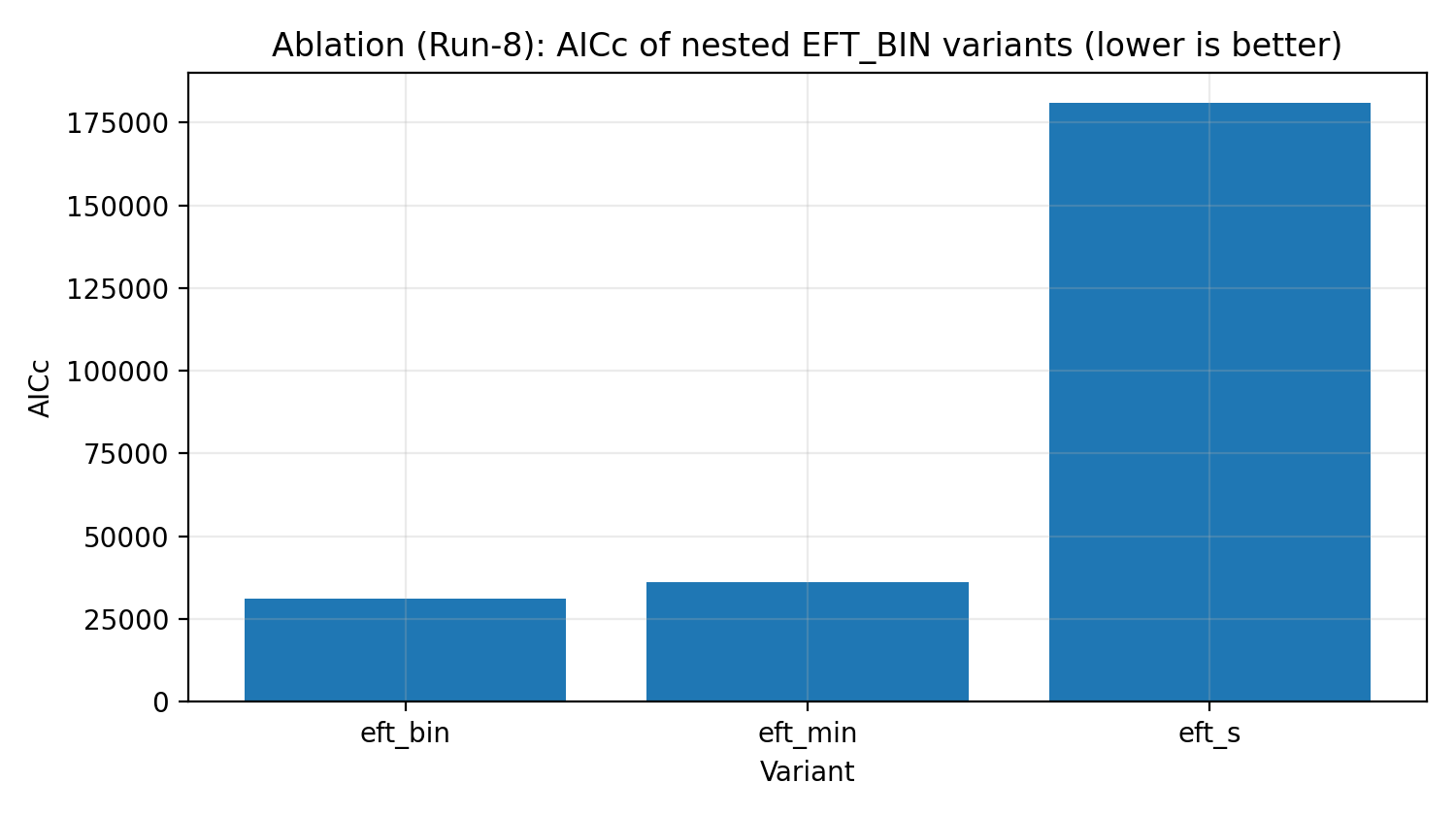
图 R5|EFT_BIN 的消融阶梯(AICc,越小越好)。
如何解读这张图 |
检验完整 EFT_BIN 是否在数据解释上具有必要性,而不是白加参数。 |
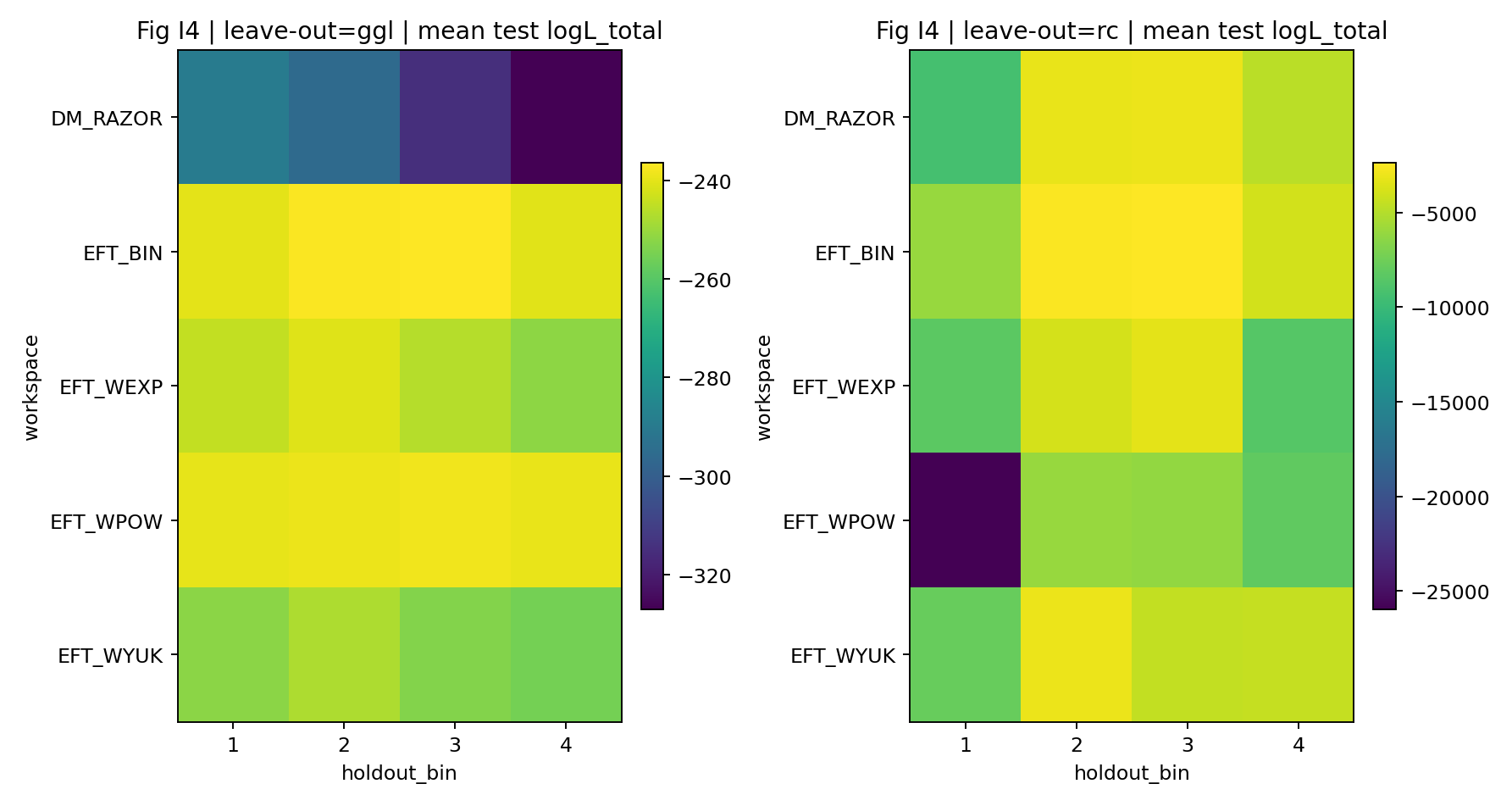
图 R6|LOO:留出 bin 的对数似然分布。
如何解读这张图 |
检验模型在未见过的 GGL bin 上是否仍具预测表现。 |
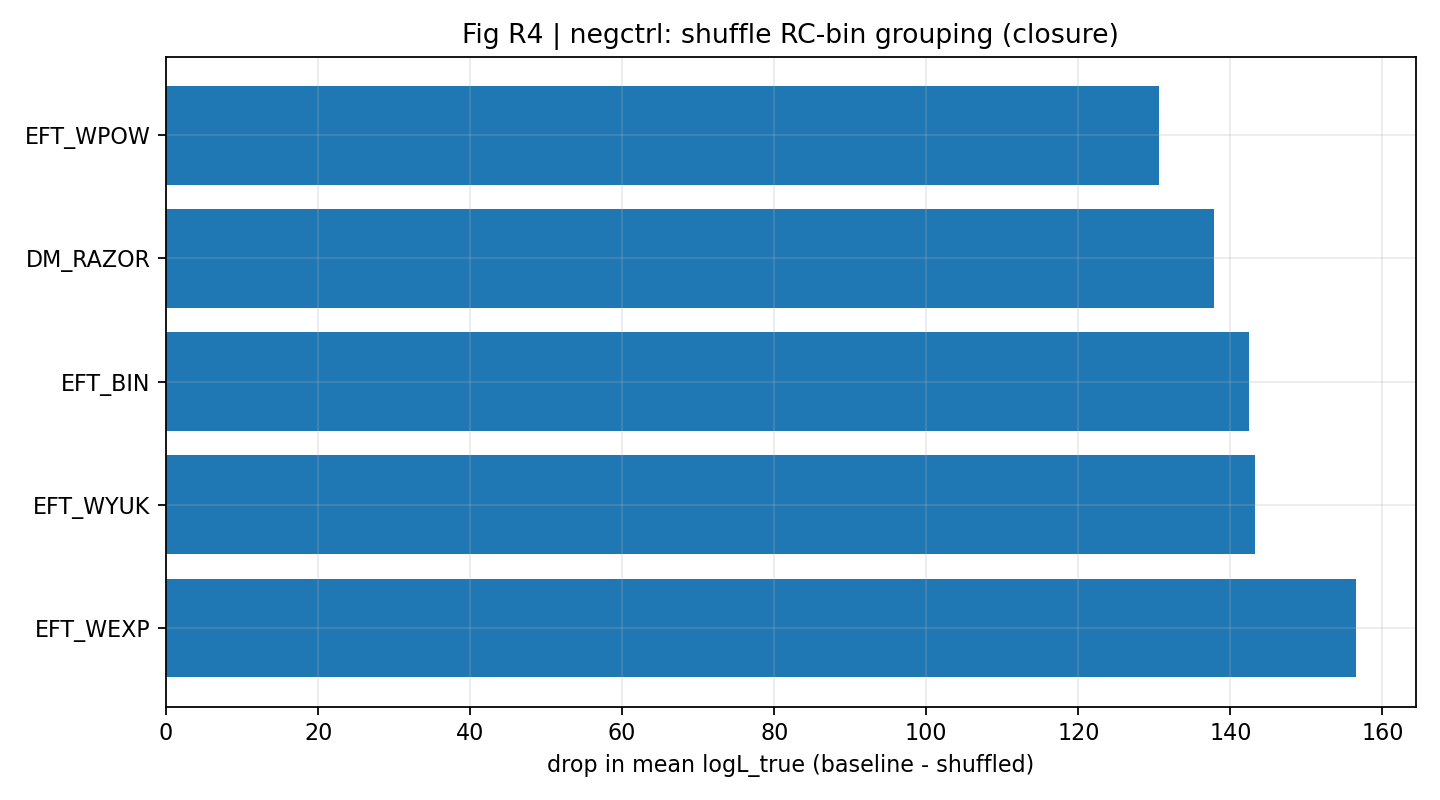
图 R7|负对照:shuffle 映射导致闭合 mean logL_true 明显下降。
如何解读这张图 |
进一步从 mean logL_true 角度显示,闭合依赖正确的跨数据映射。 |
9|P1A:为什么“附录里有多个 DM 模型”是关键修正?
这一节要回答的不是“EFT 只赢了一个最小 DM_RAZOR 吗?”而是:当我们在低维、可复现、参数账本清楚的范围内增强 DM 基线(P1A),闭合检验与联合拟合的结论会不会被改写。换句话说,P1A 的目标是降低“你只是挑了一个过弱 DM 基线”的质疑,并把讨论推进到“在一组可审计的 DM 增强下,闭合表现是否仍然存在差异”。
P1A 的设计并不试图穷尽所有 LambdaCDM 晕建模可能,也不把 DM 侧变成高维不可审计的拟合器。它选择的是低维、可复现、参数账本清楚的增强:浓度散射、绝热收缩、反馈 core、层级 c–M scatter prior、单参 core 代理、弱透镜 shear-calibration nuisance,以及组合 DM_STD。
P1A 的主要读法 |
legacy 三分支中,仅 feedback/core 对闭合强度带来小幅净提升;SCAT 与 AC 没有带来净闭合提升。 |
DM_HIER_CMSCAT、DM_RAZOR_M、DM_CORE1P 对闭合强度影响很小或没有显示显著净提升。 |
DM_STD 可显著改善 joint logL,但闭合强度下降,提示它主要提升联合拟合灵活性,而不是 RC→GGL 的迁移预测力。 |
EFT_BIN 在 P1A 表 B1 中仍保持更高的闭合强度和联合拟合优势;因此,P1 的核心主张不应被简化为“只赢了最小 DM_RAZOR”。 |
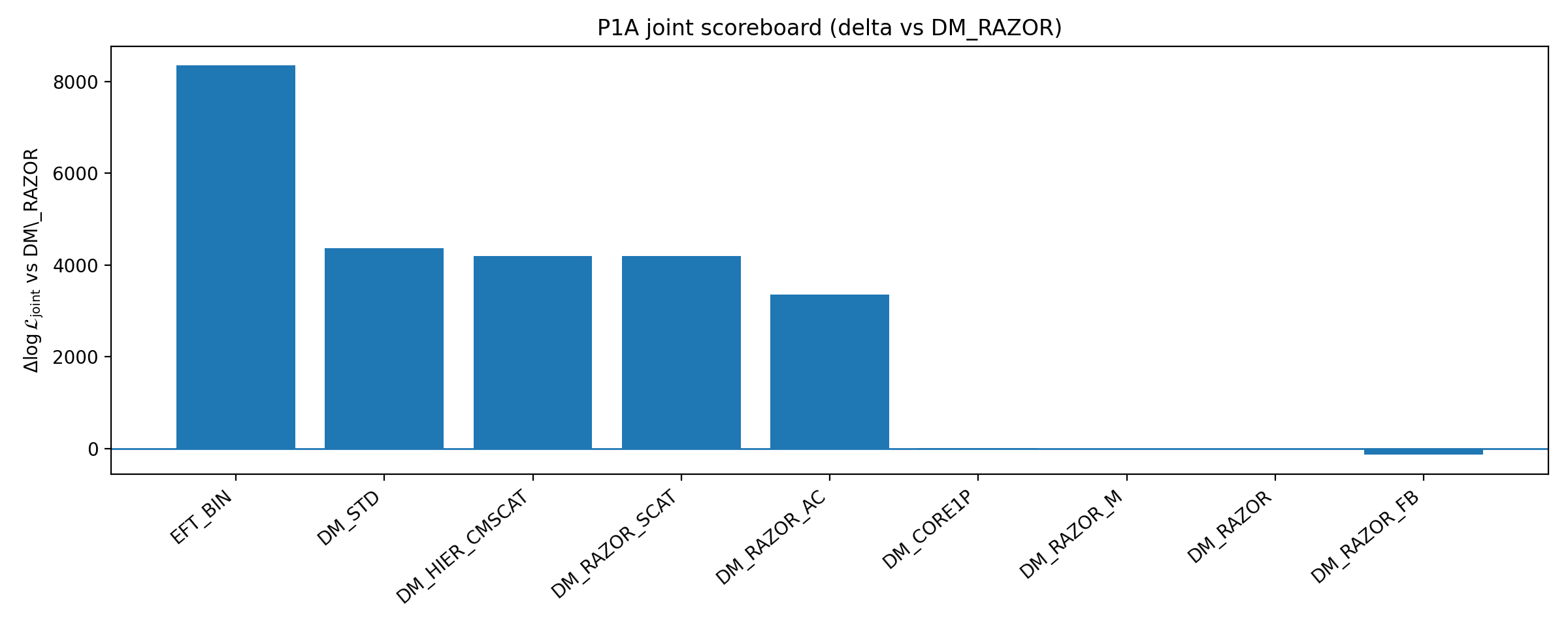
图 B1|P1A scoreboard:闭合与联合的 ΔlogL 相对 baseline(越大越好)。
如何解读这张图 |
这张图展示多个 DM 增强分支相对基线的表现。 |
它的意义不是“排除所有 DM”,而是显示:在 P1A 选择的低维可审计 DM 增强范围内,增强 DM 并没有消除 EFT_BIN 的闭合优势。 |
10|P1 实验的意义:为什么这件事值得做?
10.1 方法论意义:把“跨探针闭合”放到比“单探针拟合”更高的位置
星系尺度理论最容易陷入的争论是:某个模型能不能拟合某一套旋转曲线。P1 把问题提高了一层:你从 RC 学到的参数,能不能在不重新调 GGL 的情况下预测弱透镜?这使 P1 从“拟合竞赛”变成“迁移预测检验”。
10.2 透明度意义:把可复核链条当作结果的一部分
P1 的一个重要贡献是把数据、表图、运行标签、负对照、复现包和审计链条一起发布。对支持者和反对者来说,这都很重要:讨论可以回到同一套公开数据、同一套映射、同一套脚本和同一套指标,而不是只比较口号。
10.3 物理意义:它给“非暗物质引力”方向提供了一次强压力测试
在非暗物质引力方向,很多模型能解释旋转曲线或 RAR 的某一部分;但更难的是同时通过弱透镜读数,并在负对照下显示信号依赖正确映射。P1 的意义在于,它把 EFT 平均引力响应放进了一个类似“外部考试”的协议:RC 是训练场,GGL 是迁移场,shuffle 是反作弊场。
10.4 这是否是“非暗物质引力领域”的重要实验?
谨慎地说:如果 P1 的数据处理、复现包和闭合协议经外部复核仍然成立,那么它可以被视为非暗物质引力 / 修改引力方向中一个值得认真对待的 RC+GGL 闭合实验。它的重要性不在于一句“推翻暗物质”,而在于它给出了一个可以复制、可以挑战、可以扩展的跨探针判据。
是否已经有同样高的 RC+GGL 预测闭合框架? |
已有相关框架和观测传统:MOND/RAR 能很好组织大量旋转曲线现象,KiDS-1000 弱透镜 RAR 工作也比较了 MOND、Verlinde emergent gravity 与 LambdaCDM 模型;LambdaCDM 也可通过星系—晕连接、气体晕和反馈建模解释部分弱透镜/动力学现象。 |
但 P1 的准确主张不是“世界上没有其他框架能解释 RC+GGL”,而是:在 P1 自己公开的固定映射、RC-only→GGL 闭合、shuffle 负对照、参数账本与 P1A 多 DM 压力测试协议下,EFT 报告了更强的闭合表现。 |
换句话说,P1 最值得被外界检验的地方,是它提出了一套具体、可复现的比较协议。后续是否有 MOND/RAR、LambdaCDM/HOD、hydrodynamical simulation 或其他修改引力框架在同一协议下达到相同或更高闭合分数,是非常值得继续做的下一步。 |
11|P1 能推出什么?不能推出什么?
表 3|P1 的结论边界
可以推出 | 在 P1 的 RC+GGL 数据、固定映射和主比较协议下,EFT 系列相对最小 DM_RAZOR 具有更高联合拟合与闭合强度。 |
可以推出 | 在 P1A 低维可审计 DM 增强范围内,多个 DM 增强没有消除 EFT_BIN 的闭合优势。 |
可以推出 | shuffle 负对照显示闭合信号依赖正确跨数据映射,而非任意映射都可得到。 |
不能推出 | 不能说 P1 已经推翻所有暗物质模型。P1A 仍不穷尽非球形、环境依赖、复杂星系—晕连接、高维反馈或完整宇宙学模拟。 |
不能推出 | 不能说 EFT 完整理论已经被第一性原理证明。P1 只检验平均引力响应这一唯象层。 |
不能推出 | 不能说所有系统误差已被排除。P1 只在已列出的压力测试与审计范围内给出稳健性证据。 |
12|常见问题:普通读者最容易问的几个问题
Q1:这是不是在说“暗物质不存在”?
不是。P1 的结论必须限定在本文数据、协议和对照模型范围内。P1A 已经比最小 DM_RAZOR 更进一步,但仍不代表所有可能暗物质模型。
Q2:这是不是在说“EFT 已经被证明”?
也不是。P1 把 EFT 当作平均引力响应参数化来检验,显示其在 RC→GGL 闭合上表现更强;微观机制与完整理论不是 P1 的结论。
Q3:为什么不直接讲显著性 σ 值?
P1 使用的是统一似然得分、信息准则和闭合差值。ΔlogL 是同一评分规则下的相对优势,不等同于单一 σ 值。
Q4:为什么要打乱 RC-bin→GGL-bin?
这是负对照。真正的跨探针信号应依赖正确映射;如果打乱后仍然一样强,反而说明可能有实现偏差或统计伪信号。
Q5:P1 下一步最应该做什么?
把同一协议推广到更多数据、更多 DM 对照、更复杂系统误差和更多修改引力框架;尤其要让外部团队能在同一闭合指标下复验。
13|术语小词典
表 4|术语小词典
术语 | 一句话解释 |
旋转曲线(RC) | 星系盘中半径—转速关系,用来反推盘面内有效引力。 |
弱透镜(GGL) | 通过背景星系形状的统计性扭曲,测前景星系周围平均引力/质量分布。 |
闭合检验 | 用 RC 后验预测 GGL,并与打乱映射的负对照比较。 |
负对照 | 故意破坏关键结构,看信号是否消失;用于排除伪信号。 |
NFW 晕 | 冷暗物质模型中常用的暗物质晕密度剖面。 |
c–M 关系 | 暗物质晕浓度 c 与质量 M 的关系;是否允许散射会影响模型灵活度。 |
DM_STD | P1A 中组合多个低维 DM 增强与透镜 nuisance 的标准化 DM 压力测试分支。 |
ΔlogL | 两个模型在同一评分规则下的对数似然差;正值表示前者更优。 |
协方差 | 数据点之间相关性的矩阵描述;弱透镜数据通常必须使用完整协方差。 |
14|建议阅读路线与引用入口
1. 先读本文第 0–2 节,建立 P1 的问题意识和 EFT 在 P1 中的克制定位。
2. 再看图 S3、图 S4 与表 S1a/S1b,理解闭合强度、联合拟合与负对照。
3. 如果关心“DM 基线是否过弱”,直接看第 9 节和表 B1 / 图 B1。
4. 如果要技术复核,请回到 P1 技术报告 v1.1、Tables & Figures Supplement 与 full_fit_runpack。
主要归档入口 |
P1 技术报告(发布级,Concept DOI):10.5281/zenodo.18526334 |
P1 全量复现包(Concept DOI):10.5281/zenodo.18526286 |
EFT 结构化知识库(可选,Concept DOI):10.5281/zenodo.18853200 |
许可提示:技术报告采用 CC BY-NC-ND 4.0;全量复现包采用 CC BY 4.0(以技术报告与 Zenodo 归档为准)。 |
15|参考文献与外部背景
McGaugh, S. S., Lelli, F., & Schombert, J. M. (2016). The Radial Acceleration Relation in Rotationally Supported Galaxies. Physical Review Letters, 117, 201101. DOI: 10.1103/PhysRevLett.117.201101.
Famaey, B., & McGaugh, S. S. (2012). Modified Newtonian Dynamics (MOND): Observational Phenomenology and Relativistic Extensions. Living Reviews in Relativity, 15, 10. DOI: 10.12942/lrr-2012-10.
Brouwer, M. M., Oman, K. A., Valentijn, E. A., et al. (2021). The weak lensing radial acceleration relation: Constraining modified gravity and cold dark matter theories with KiDS-1000. Astronomy & Astrophysics, 650, A113. DOI: 10.1051/0004-6361/202040108.
Mistele, T., McGaugh, S., Lelli, F., Schombert, J., & Li, P. (2024). Indefinitely Flat Circular Velocities and the Baryonic Tully-Fisher Relation from Weak Lensing. The Astrophysical Journal Letters, 969, L3 / arXiv:2406.09685.
Bullock, J. S., & Boylan-Kolchin, M. (2017). Small-Scale Challenges to the LambdaCDM Paradigm. Annual Review of Astronomy and Astrophysics, 55, 343–387. DOI: 10.1146/annurev-astro-091916-055313.
Lelli, F., McGaugh, S. S., & Schombert, J. M. (2016). SPARC: Mass Models for 175 Disk Galaxies with Spitzer Photometry and Accurate Rotation Curves. The Astronomical Journal, 152, 157. DOI: 10.3847/0004-6256/152/6/157.
Navarro, J. F., Frenk, C. S., & White, S. D. M. (1997). A Universal Density Profile from Hierarchical Clustering. Astrophysical Journal, 490, 493.
Dutton, A. A., & Macciò, A. V. (2014). Cold dark matter haloes in the Planck era: evolution of structural parameters for NFW haloes. Monthly Notices of the Royal Astronomical Society, 441, 3359–3374.